Free SEO audit of your website by powerful entry-level tools
- SERP analysis by yourself
- Core Web Vitals metrics
- Crawlers: the best and free
- On-Page SEO checkup on the fly
Contrary to popular belief, SEO is not only about building links and working with copywriters. The first task for the optimizer is the website’s health checkup in the broadest sense. And you can do it yourself!

The initial SEO audit begins with a check to see if the following conditions are met:
- All useful pages are open to search bots, while auxiliary ones are closed.
- Search Engine bots get everything they need to render the page (HTML, CSS, JS) fast enough.
- The website is mobile-friendly and accessible (adapted for screen readers).
- It’s clear from the site architecture which pages are principal and how others are related to them.
- Each page, including paginated ones, has properly filled-in meta tags, a title, and a canonical link.
- In the content or navigation, there are no links to non-existent pages (so-called broken links or 404 errors).
- The URLs are human-friendly; every adult can read them and perhaps even remember.
- The pages don’t have a lot of overlapping content, or each group of “twins” refers to a shared canonical page.
- None of the elements you can interact with (sorting buttons, preset bars, etc.) generate duplicate pages with different URLs.
- The Search robots know the purpose of each button on the site and can read what the illustrations show.
Of course, this is just the most basic SEO analysis. If the website was created with Web Search in mind, all those checkmarks should be fulfilled by default. However, not all developers, let alone online website constructors, think about it. Therefore, we can’t do without a technical SEO checkup.
If you are too busy to audit the site right now, test the site with the Siteliner. It’s free, and you’ll do it with a mouse click. At least you’ll be sure there are no broken links on your site. Come back when you have free time; we’ll analyze the website as it should be!
In fact, all the dirty work is usually done by special software – the Web crawler. A human SEO auditor’s job is to advise developers on how to improve the site so that it is more understandable to search engines. More about web crawlers can be found below, but here I’m saying that, for small websites, a simple study of the Google SERP may be beneficial.
Site-wide search and SERP analysis: how does the site appear on Google?
If you have a small website and a similar budget to maintain it, you can easily perform a complete SEO audit by yourself. Type site:your-website into the Google search bar and take a close look at the results.
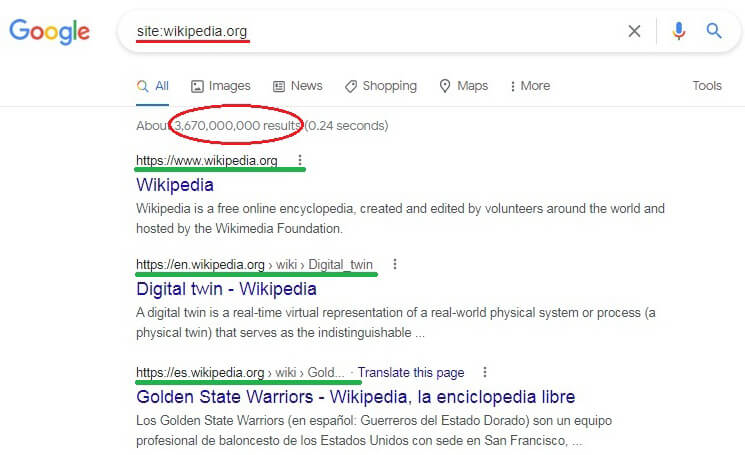
- Are all your significant pages on Google SERP?
- Do any snippets have identical titles or descriptions? The title and description must be declared at the head of the HTML document and must be unique.
- Haven’t some sensitive data (customer database, order list, etc.) happened to be among the results? If so, it’s necessary to submit a request to remove the URL, block access and prohibit indexing.
The rows above the blue headers do not show real web addresses: they are generated from the breadcrumbs (more about navigation chains here). To see the full URL hover the mouse over the correspondent blue link on SERP.
Look carefully at those navigation lines of snippets (highlighted in green in the picture).
- Perhaps there are URLs with www and without www? You can’t leave it like this!! The whole site should follow the same principle: either all URLs start with www or none.
- Same with https: and http:. If both protocols are present, the site has not entirely “moved” to HTTPS, and you need to keep an eye on the progress.
- Are there parameters in URLs? I mean, don’t you see the question mark “?” followed by one or more equal signs? It might look like «?v=19243242.twr&rt=AA&s=price»? Even if you see them, it’s not harmful yet, but just not nice.
But if you find two different web addresses built according to the templates
your-website/.../?x=cat & y=dog і your-website/.../?y=dog & x=cat ,
open both. Are they identical? – This is a classic example of duplicate content and a reason to contact the developer. They will have to reconfigure the URL construction rules and stick together indexed duplicate pages with a 301 redirect.
Keep inURL search bookmarklet: I use it to get a list of URLs with query parameters («?search=») or mistakenly indexed pages («/admin») on Google. Drag the script to the bookmarks bar and run it from any page of the domain google.com. This form will pop up.
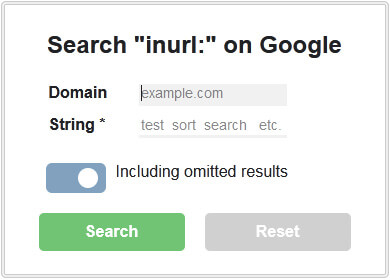
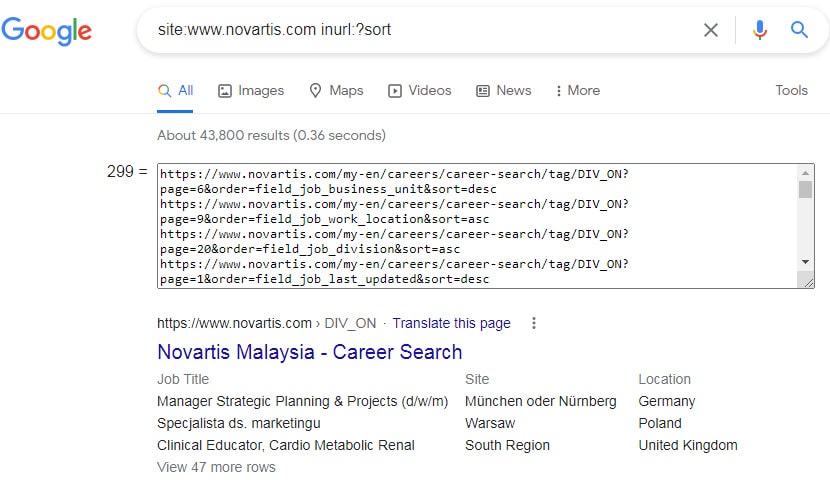
Specify one or several query strings: the script will walk through the search results and write the URLs into the <textarea>, where you’ll copy them easily. Here is an example of a website that hasn’t prevented sorting from indexing.
If you own the site you are inspecting on SERP, Google will invite you to try the Search Console. That’s right: you should investigate Webmaster Tools to learn how the Search Engine indexes pages, whether it sees Schema.org markup on them, and so on.. Google Search Console will inform the webmaster about the problems found on the site by email, but unfortunately, with a long delay. Also, it would be useful to have your site tied to Bing Webmaster tools.
Core Web Vitals. Website performance checkup
Relevant and high-quality content is always #1. However, if the website is slow, it won’t be easy to get high positions on Google SERP. As back in 2021, Google stated that Core Web Vitals (load speed, interactivity, layout stability) had become important ranking factors.
Thus the first step is to check the performance of the site’s homepage and all typical pages, such as categories, products, etc. There is a service, Pagespeed Insights: it identifies performance bottlenecks and suggests ways to get rid of them.
For perfectionists, I recommend a multi-purpose alternative to this tool, Web.dev Measure: in addition to performance, it’ll verify the page’s accessibility for screen readers, check the source code quality, and validate the main aspects of page-level SEO. Update! Google has decided to shut down this service, completely transferring the functionality to Pagespeed Insights (see the link above).
For example, here are the scores of the PACE website.
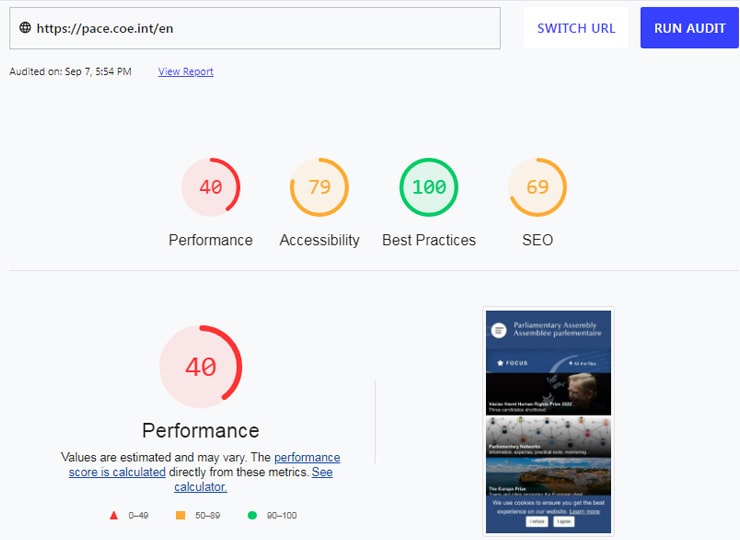
It’s a little rough, but although it’s not visible in the screenshot, the criticism is highly constructive. In the report, every estimate is broken down into components, and for them, recommendations for improvement are given.
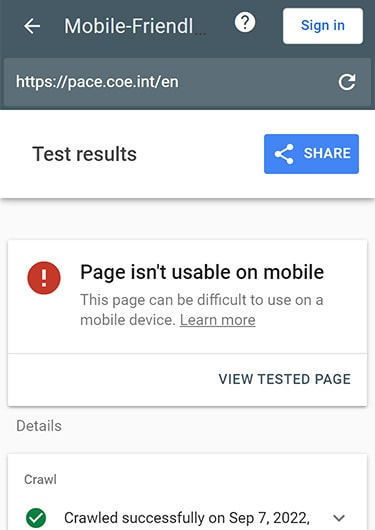
The next step is to make sure the site is optimized for mobile. Here is a service from Google: Mobile-friendly Test will show the page as seen by Googlebot for smartphones. After checking the PACE website, we see that mobile bots have absolutely nothing to do here.
Another service, Yellowlab Tools, can help with site inspection. It relies on the headless browser and evaluates essential performance metrics. It also verifies the implementation of best coding practices and provides you with a structured list of recommendations. For testing, you can select the Desktop, HD, Smartphone, or Tablet mode.
Bookmarklets for submitting pages for testing: Pagespeed * Mobile * Yellowlab. Bookmark the link and run the script from the page you want to check.
If the results of your website analysis turn out to be unoptimistic, you will have to contact the developer with a complaint or look among your friends for a front-end expert.
It’s also worth measuring the server response delay, load pages in parallel to compare, etc. – it’s all here on Webpagetest. Don’t want to dive too deep? Then turn to Pingdom: it outputs straightforward answers.
Anyway, failed tests do not mean the end of everything. Websites can still rank high due to inbound links and content quality. But shortly, it will be more difficult, so it’s better to correct the wrongs as soon as possible!
The best free and powerful web crawlers
There will be mentioned not just totally free crawlers but also free-trial soft that you can use to a limited extent without any charge. With the help of these programs, you’ll perform an SEO audit of your website like a pro. The difficulty may be in how to interpret the report and how to fix errors without harming anything.
Before you open any program, please review the terminology. The absolute bare minimum:
- rel="canonical" is the attribute of a <link>. Such a link refers to the principal page among a bunch of similar ones.
- redirect is a technique that allows forwarding the original page request to another URL. It may be temporary (302) or permanent (301).
- robots.txt is a plain text file in which we can disallow one or more bots from accessing pages, files, or directories on the website.
- noindex is a directive that demands to exclude the current page from the index.
- sitemap.xml is a list of all indexed pages; it’s located in the root directory of your site.
- hreflang is an attribute of the link tag that specifies the page’s language.
Now it’s time to choose a software platform among cloud-based and desktop web crawlers. To see your site as Google sees it, or to avoid blocking, they can pretend to be the Google bots, spoofing the User Agent string. But the cheating can be exposed by additional verification.
Cloud-based crawlers
They’re indispensable for large websites with hundreds of thousands of pages. Of course, no one will provide free crawling on such a scale.

However, Teracrawler lets you check up to 10,000 URLs for free, and Oncrawl will offer 14-day trial access to the platform. I would also emphasize the Ukrainian cloud-based crawler Sitechecker. It is easy to set up and positions itself as the best choice for online commerce, but the trial period is only 7 days.
Desktop crawlers (or spiders)
It’s the most suitable option. But the crawl speed will be limited by the computing performance of your PC. For brevity, I’ll name only three SEO software providers worth your attention.

- Sitebulb auditor: it probably has no equal in classifying errors, explaining possible reasons for them and potential harm from them. It reveals the hidden flaws of the site, draws a graph map, and sorts through everything else. The owners of the tool offer a two-week trial.
The disadvantage for a beginner is that Sitebulb’s report will provide you with an ocean of information in which you can drown without practicing first. If you don’t like to go deep into details, it might be better to start with another program.
- Screaming Frog and Netpeak spiders have much in common. The first is older and more widespread; the second has been created to replace the leader: perhaps, it’s better adapted for some local tasks. For basic SEO analysis, the differences between the programs are insignificant.
Both tools require decent payment. But Netpeak offers a 14-day trial, while Screaming Frog gives the long-lived free version that tests no more than 500 URLs from the same domain.
I believe, using the services listed, you can perform an SEO audit on a website even if it’s built by a Javascript framework like Angular.
On-page SEO: test the page on the fly with bookmarklets
Let’s imagine that the crawling reports have already been obtained, and we want to check problematic pages manually. Fans of easy solutions will ask Google if it knows “how to check on-page SEO online”.
However, if the previous steps of analysis have been completed, I do not recommend looking for additional tools. There is nothing significant to add to the reports from clawlers and code inspectors. But On-page SEO validators will probably find “multiple flaws” and recommend adding five words to the first paragraph, and so on. But that’s just a field of subjectivity, and we are talking about technical SEO.
1. Rational requirements for title, description, and keywords are discussed in the post on SERP snippets. Here I share the bookmarklet that shows Title+meta-tags+canonical of the current page. It will be usable when you drag it to the browser bookmarks bar.
If the canonical link href doesn’t match the current URL, then the current page recommends the Search Engine to rank another one instead. It must be a conscious choice! Canonicalization will only work for pages with similar content and a common purpose. If you’re thinking of using a generic canonical URL to deal with the indexed pagination issue, it’s worth taking a look at the cited page.
2. The next step is to check up page links, including the outbound ones. Here is the bookmarklet All-page-links: it’ll open a new window with the list of page links together with iconic buttons. For them, the text from the attributes title and aria-label will be used instead of the anchor.
If there are nameless iconic buttons on the website, they must be accessible to those who can’t see or load that symbol. That means the button element must have an attribute with some description for screen readers.
3. Let’s look at the headings and other marked-out text on the page. If, for example, we only see <h1>,<h3> but not <h2>, this is a mess! Headings are for structuring: you can’t use, say, <h3>, only to make the font bigger or center the text. Besides, the text markup has its fine points.
HTML tags <strong> and <em> are semantic, while their twin brothers <b> and <i> are just decorative. The text highlighted by them looks the same: bold-faced /b, strong/ or italic-type /i, em/, but it might make a difference for Search robots.
So, the bookmarklet will come in handy: H1-h6, strong, b, em. It will paint the subheadings and other semantic tags, as well as ordinary bold-faced text on the page. Look closely: maybe somewhere <b> should it be replaced with <strong> or vice versa?
4. It’s necessary to check whether the illustrations have alt-attributes filled in. There is a script bookmark: Alt text for images. It will replace pictures with descriptions or warn that no alt text is specified.
Search engines can recognize images, but not perfectly yet. Besides, the visitor to the site may not be able to load a photo; how would they know what was on it? For this, the image must have an alt text: alt=“The man rushes to apply his knowledge of technical SEO”. If the loading fails, the text will be displayed instead of the image.
There are many more nuances, but for a not-so-large website audit, this SEO knowledge is enough. If you feel something is missing, please don’t hesitate to comment; we’ll complete this guide together.
The cover image of the post was generated by OpenAI’s Dall-E2.
